As discussed before, seeding tends to enhance fairness (C), which measures the tendency of a tournament to distribute its rewards to the better players, at the expense of fairness (B), which measures the extent to which every entrant is given an equal chance.
But the extent to which the better players are given an advantage is not uniform through the skill distribution. Seeding creates a pattern of advantages and disadvantages that affect different parts of the skill distribution differently.
Take, for example, the fate of the number 8 – 12 seeds in the annual NCAA basketball tournament. Considering only the first round, it’s better to be seeded 8 or 9 than 10, 11, or 12. But whichever of the 8 or 9 seeds wins their first round match against each other then will almost certainly face the number 1 seed in the next round. 10, 11, or 12 seeds that get by the first round will have an easier opponent in the second round. Thus, despite facing a tougher first-round opponent, experience shows that the 10, 11, and 12 seeded teams are actually somewhat more likely to reach the “sweet 16” than the 8 or 9 seeds.
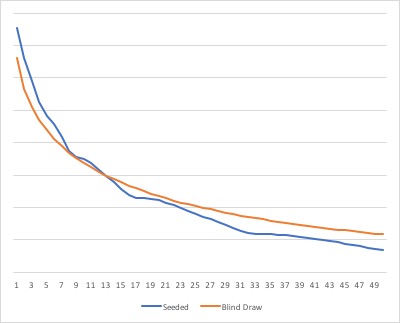
Here is a chart that shows the log of the expectations for the top 50 players in a hypothetical U.S. Open tennis tournament, run both as a blind draw, and as a fully-seeded tourney. The red curve for the blind draw tourney is smooth, representing a more or less gradual decline in the player’s expectation. The blue curve for the fully seeded tourney shares this basic pattern, but also shows a secondary effect that makes the line a bit wavy. To make the wave pattern clearer, here’s another chart, showing differences in the log of the expectations, this time for the full 128-player draw:

The benefit of better seeding comes and goes, on a period relating to the powers of two. In general, it’s less desirable to be the 9th, or the 17th, or the 32nd, or the 65th seed because that tends to give you matches against top-ranked players.
Depending on the parameters of the competition, this wave can be large enough that it’s actually desirable, in terms of overall expectation, for a player to have a lower seed than a higher one. In the hypothetical U.S. Open simulation, this wave effect overcomes the general decline at only one position, and there just barely. The expectation for the 17th seed is $188,616, and for the 18th it is $189,223. Otherwise the expectation curve declines monotonically.
But the possibility that a player might do appreciably better with a lower seeder than a higher one is a matter of concern for tournament administrators. If the U.S. Open were run as a fully-seeded tourney, it might well be desirable for a player to throw a match at the Western and Southern in order to avoid creeping up into an undesirable seeding position.
This, then, might be a good reason for the unusual tiered seeding procedure used by professional tennis. By randomizing the positions of seeds 17 through 32, for example, there can be no incentive for a player to seek a lower seed (and a very strong incentive to break into the next-higher seeding tier by reaching number 16).

Documentation released by the NCAA in October 2018 (“how-field-68-teams-picked-march-madness”) says, for all intents and purposes, that teams are set in groups of 4; but the highest team within each group gets a geographic advantage, so long as it would put a Top 16 team at a “home field disadvantage”. And, Conference Play is prohibited in the First Round (outside of the First Four) and restricted in Rounds 2 & 3. This effectively randomizes each individual seed line of four relative to the Top Line (though that Top Line is still set.)
Combining the At-Large Play-Ins as a single team each, (because where they would fall varies, last year they occupied spots 41 and 42, SB Nation’s Bubble Analysis defaults to giving them spots 43 & 44,) the seed lines become {1, 2, 3, 4, {5, 6-8}, 9-12, 13-16, 17-20, 21-24, 25-28, 29-32, 33-36, 37-40, 41-44, 45-48, 49-52, 53-56, 57-60, {61-62, 63-64, 65-66}}.
There are some restrictions, hence the second tier of {brackets}: 5 is effectively protected from being in the same region as 1 unless 2-5 are all in the same Conference. And while the worst 2 auto-bids would have to play each other and the next 2 worst have to play each other, which region each ends up in is determined by the geographic preference of the other 2 teams in the #16 line. As an example, UMBC, who beat #1 overall Virginia last year, did NOT play in a First Four game; UMBC was the Highest of the 6 #16 seeds. If it was a true S-Curve, they would have faced Xavier instead who actually got the worse #16 Play-In. (Side note: The sports-talkers I heard from left me with the impression that the game was a demonstration of the old Boxing adage “Styles make Fights” with UMBC’s style being the Paper that covered the Cavaliers’ proverbial Rock.)
I would imagine that, with so many tiers, the magnitudes of the seeding waves would be reduced, but the waves would “spread out” more. Sort of like a “stretched-out” version of the fully-seeded 16.
I also wonder what would happen to the seeding waves if the bracket was “reset” after each round, i.e. each surviving entrant was reseeded based on their rank relative to the entrants not yet eliminated.
LikeLike
The way that the NCAA committee fills the bracket seems a likely opportunity for abuse, at least around the margins. It violates the new fourth maxim because the committee is working things out only after they know the identities of the teams involved. I suppose it helps a little for them to publish rules like the ones you describe, but I’m still inclined to worry – those committee members are scarcely disinterested outsiders.
I take the point that considerations other than strict team quality affect which region a team goes to. That makes the seeding of the NCAA work more like seeding in 4-team tiers than strict 1-68 seeding. I think you’re right that each regional 16 bracket the seeding ends up being pretty conventional full seeding, and that’s bad enough from my point of view.
I know that some have suggested that the seeding be refreshed each round – they do that for the NFL playoffs. Whatever the other merits, however, the NCAA would never do this because it would make it impossible to run the kind of office bracket pool that’s found almost everywhere, and that would cut deeply into fan interest (and hence television revenue).
LikeLike
I concede the point about the Committee seeding teams only after their identities are known. I would prefer awarding Conferences At-Large slots based on their postseason performance over the prior 3 years, as Bill Connelly of SB Nation has suggested and UEFA does for their annual Club Soccer Tournaments. I would extend this allocation throughout all of the Basketball tourneys, but I would not necessarily use the same method that UEFA does. I would then allocate the bids within each Conference based primarily on Regular play, but with allocations for the Tournament Winner and Runner-Up.
After that, within each tournament, I would have initially seeded teams strictly according to NET (RPI prior to this year). However, reading through your blog has made me reconsider that stance. I would place the Conference Tournament Winners in one partition and the At-Larges in another. I would then order these partitions according to NET. For the Champions, the split would be {1-16, 17-28, 29-32}; for the At-Larges, the split would be {1-32, 33-36}. The bottom partition of each form the “First Four” Play-Ins; the At-Large Play-Ins getting 2 of the #13 Lines and the Champion Play-Ins getting 2 of the #16 lines. The {17-28} Champion Tier would form the other #13-#16 lines, while the Top Tiers of each partition would be combined into the “General Population”. How the seeding would progress further has been altered by a revelation I made further down, allowing me to set the non-bottom tiers as {1, 2, 3-4, {5, 6-8}, 9-12, 13-16, 17-32, 33-48}. Within each tier, (including the Bottom tier and subject to the Play-Ins and certain Principles that I could retain,) the teams are assigned Geographic Preference in order of NET. (Yes, this creates the possibility that 17-20 could all be in the same region; but so does random sortition.)
As for refreshing seeds, given how the tourney is now, I would only suggest refreshing seed in Rounds 3 and 5, and for Round 3, only within each respective region. i.e. if you were originally in the Midwest Region, you would still go to Kansas City for Rounds 3 & 4, not Anaheim. Reseeding Rounds 2 & 4 would cause a heavy logistical strain, and also see the next paragraph; Reseeding the Finals is pointless. As for the bracket pools, I have one word: Javascript. (Then again, seeding all teams allows me to just roll a 20-sided die to fill out my bracket; the Target Number would be based on prior results of specific seed matchups.)
Granted, being able to fully reseed in Round 3 could be supported as well, but that would only allow teams to know their Round 3 destination on the Monday following Round 2. This could have teams that played on Sunday have to turn around and play on Thursday instead of Friday. If they faced an opponent who last played on Saturday, that would be a legitimate Fairness(A) concern due to the differences in rest days. Granted, even with that concern in play, you could allow reseeding between the 2 regions that play on the same days. But if you do that, you might as well have the winners of the Thursday regions meet in the 1st Semifinal and the winners of the Friday regions meet in the 2nd Semifinal regardless of seeding. This would force the #1 overall and the #2 overall to play on different days, unless you are willing to throw out Fairness(C) altogether.
Actually, forcing #2 to play on different days from #1 and aligning the Semis based on “Days Played” could be a beneficial modification. It would allow for an actual {3-4} tier instead of having the 2 places be separate tiers: Once the Top 2 teams have their picks, (#2 would be restricted to the venues that are not played on the same day as #1 is playing,) #3 gets their choice from among the remaining 2 Regions, 1 playing on the same day as #1, 1 playing on the same day as #2. Under my system #2 and #3 would only know which 2 regions are unavailable at the time of their respective picks. Yes, this creates a Fairness(A) concern for #2, in that its geographic mandate is significantly reduced (choice of only 2 regions instead of 3). This could even be a Fairness(C) concern, as Home Court still has a demonstrated impact on skill level in College Basketball; the NCAA has recognized this in the formation of the NET tiers and by the Principles explicitly protecting the Top 16 overall from having a “Home-Field Disadvantage” in Round 1. However, the Principles also prohibit a team from playing on its Home Court outside of the Final Four and the Principles explicitly grant only the #1 overall seed the privilege of region preference.
LikeLike
I’ll have a post or two about March Madness again this year – I think I may have an even more outlandish suggested bracket to offer, but I’m still a bit vague on the details.
Would you consider being tourneygeek’s first-ever guest author for a March Madness post? I have some thoughts about how this might work – drop me a line by regular email if you’re interested.
LikeLike